
Modele LLM a język polski. Test wykazał, które radzą sobie najlepiej
Większość najpopularniejszych modeli sztucznej inteligencji wykorzystywanych do pracy z tekstem powstaje w Stanach Zjednoczonych lub w Chinach, ale korzystają z nich użytkownicy na całym świecie – także w swoich ojczystych językach. W praktyce oznacza to, że systemy trenowane głównie na danych anglojęzycznych muszą radzić sobie z różnymi strukturami gramatycznymi, stylem komunikacji i kontekstami kulturowymi. Efekty ich pracy bywają zróżnicowane, czego dowodzi test przeprowadzony przez Marka Jeleśniańskiego, założyciela firmy Oxido, eksperta i szkoleniowca w zakresie korzystania z AI.
W analizie porównano kilkanaście popularnych modeli AI działających w ramach swoich oficjalnych chatbotów, m.in. model GPT od OpenAI, Gemini od Google, Claude stworzony przez Anthropic, a także polskiego Bielika. Celem testu było sprawdzenie, jak te modele radzą sobie z generowaniem treści po polsku w warunkach, w jakich korzystamy z AI najczęściej, czyli przez interfejs webowy.
Każdy model otrzymał identyczny zestaw zadań. Obejmowały one zarówno pytania sprawdzające znajomość polskiej historii, literatury i realiów społecznych, jak i zadania wymagające praktycznego użycia języka – od korekty błędów i analizy faktów po przygotowanie biznesowej wiadomości e-mail czy scenariusza krótkiej reklamy. Wśród poleceń znalazły się także zadania wymagające dedukcji oraz kreatywności, takie jak stworzenie żartu osadzonego w polskiej codzienności. Ocenie podlegała nie tylko poprawność odpowiedzi, lecz także płynność wypowiedzi, spójność argumentacji oraz naturalność języka.
„Pomoże” czy „Pomorze”? Detale, które sprawiają trudność modelom AI
Język polski dla wielu modeli językowych stanowi większe wyzwanie niż angielski. Wynika to przede wszystkim z jego złożonej struktury gramatycznej i rozbudowanej fleksji. Dodatkową barierą pozostaje relatywnie niewielka liczba danych treningowych dostępnych w polszczyźnie, co utrudnia modelom uchwycenie subtelnych niuansów stylistycznych i idiomatycznych. W praktyce oznacza to, że system, który w języku angielskim generuje treści niemal bezbłędnie językowo i znaczeniowo, w języku polskim może popełniać subtelne błędy stylistyczne, upraszczać znaczenia lub gorzej radzić sobie z faktografią.
Jedno z zadań testowych polegało na korekcie tekstu zawierającego liczne błędy językowe. Celowo umieszczono w nim m.in. niepoprawne zapisy nazw własnych („wielkopolski”, „merdecesa”), błędną odmianę nazwisk („Jana Kowalski”), nieprawidłowe formy fleksyjne oraz literówki w specjalistycznym słownictwie. Aby poprawnie wykonać zadanie, model AI musiał nie tylko rozpoznać błędy ortograficzne, lecz także zastosować zasady odmiany nazw własnych, interpunkcji i zapisu bardziej złożonych wyrażeń.
– Korekta trudnego tekstu w języku polskim pozostaje dla modeli językowych stosunkowo wymagającym zadaniem – mówi Marek Jeleśniański, założyciel firmy Oxido. – W tym konkretnym przypadku najlepiej poradził sobie model Llama firmy Meta. Relatywnie wysoki wynik osiągnął także EuroLLM, wyprzedzając polskie modele, w tym Bielika.
Inaczej wyglądały wyniki drugiego zadania językowego. Modele otrzymały trzy pary słów i miały wskazać poprawną formę oraz uzasadnić swój wybór. Najtrudniejsze okazało się zestawienie trzecie – „pomoże” oraz „pomorze”, gdzie druga forma została celowo zapisana z małej litery, co stanowiło błąd ortograficzny. Część modeli wskazywała oba słowa jako poprawne, stwierdzając, że „pomorze” jest nazwą geograficzną, przeoczając brak wielkiej litery. W tym zadaniu Bielik znalazł się wśród najwyżej ocenionych modeli, wyprzedzając m.in. Groka 4.2, Gemini 3.1 Pro oraz DeepSeek V3.2.
– Błędy modeli AI w rozróżnianiu „pomoże”, „Pomorze” oraz błędnego „pomorze” pokazują, że sztuczna inteligencja wciąż mierzy się z niuansami – wyjaśnia Marek Jeleśniański. – Współczesne modele korzystają z tokenizerów, które widzą wielkość liter. Jednak ich mechanizmy czasem przedkładają znaczenie słowa nad jego ścisłą ortografię. Myślę, że najprościej można to opisać tak: model skupia się na tym, że słowo oznacza istniejący region geograficzny, i „dopowiada” sobie resztę, ignorując błąd ortograficzny.
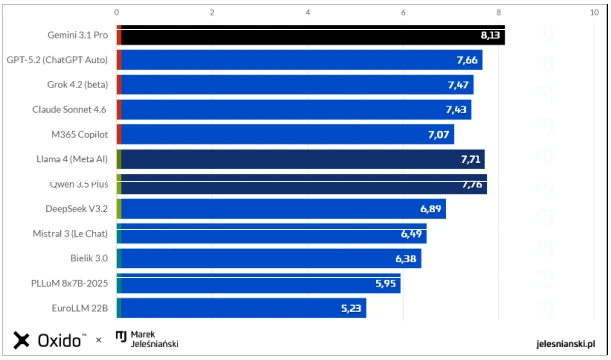
Wyniki ogólne na bazie średnich ze wszystkich zadań
AI w polskim biznesie
W teście znalazły się również zadania sprawdzające zastosowanie modeli językowych w praktyce biznesowej, m.in. w marketingu i analizie przepisów podatkowych. W części marketingowej systemy miały przygotować treść prezentacji dotyczącej kampanii promocyjnej dla lokalnego produktu. Ocenie podlegały m.in. koncepcja działań marketingowych, propozycje kanałów sprzedaży, sposób przedstawienia budżetu oraz spójność całej strategii.
Najwyższy wynik w tym zadaniu uzyskał Qwen, model rozwijany przez chińską firmę Alibaba. Stosunkowo zbliżone rezultaty osiągnęły także modele Mistral, Gemini, Grok, GPT-5.2 oraz Llama. W tej części testu polskie modele – Bielik i PLLuM 8x7B-2025 – znalazły się natomiast w dolnej części zestawienia. Różnice w ocenach wynikały m.in. z nieprawidłowego sposobu interpretacji polecenia. Na przykład, model Claude 4.6 wygenerował gotową prezentację zamiast samej treści slajdów.
Kolejne zadanie dotyczyło zastosowania polskich przepisów podatkowych w praktyce i polegało na wskazaniu właściwych stawek VAT w dwóch opisanych sytuacjach biznesowych. Większość modeli udzieliła poprawnych odpowiedzi. Najwyższy wynik (9,5) uzyskały chiński Qwen 3.5 Plus oraz amerykański ChatGPT. Podobną punktację otrzymał również polski Bielik – 9,4. Częściowo nieprawidłowe odpowiedzi pojawiły się w przypadku DeepSeeka oraz Mistrala, natomiast w przypadku EuroLLM doszło do halucynacji i model wygenerował nieistniejące ulgi podatkowe.
Najlepsi najwięksi, ale…
Wyniki testu pokazują, że wiele współczesnych modeli językowych osiąga bardzo wysoki poziom w wielu różnych zadaniach – od analizy językowej, przez interpretację informacji, po przygotowywanie materiałów biznesowych. Różnice między systemami pojawiają się głównie w bardziej szczegółowych aspektach, takich jak sposób interpretacji poleceń, precyzja odpowiedzi, kreatywność czy zdolność do pracy w określonym kontekście językowym i kulturowym.
W ogólnej czołówce zestawienia znalazły się przede wszystkim chatboty i powiązane z nimi modele rozwijane przez największe firmy technologiczne z USA i Chin. Wysokie miejsca zajęły m.in. systemy Qwen i Llama, które – w przeciwieństwie do części konkurencyjnych rozwiązań – mogą być instalowane we własnej infrastrukturze. Tego typu modele stanowią wartą rozważania opcję dla firm, które muszą zachować pełną kontrolę nad danymi i środowiskiem technicznym. Najlepsze modele jednocześnie są najczęściej największe i wymagają bardzo dużych zasobów.
– Znaczenie ma nie tylko sam model, ale całe środowisko pracy, które oferuje dane narzędzie. ChatGPT wciąż wyróżnia się pod względem funkcjonalności i możliwości personalizacji. Z drugiej strony mocną stroną Gemini i Copilota jest możliwość szerokiej integracji z popularnymi pakietami biurowymi – mówi założyciel firmy Oxido.
Wyniki analizy pokazują również skalę wyzwania stojącego przed europejską branżą AI, jeśli chce się ona liczyć w światowych rankingach. Chociaż w Europie, także w Polsce, powstają własne modele językowe, rywalizacja z systemami rozwijanymi przez największe firmy z USA i Chin wciąż pozostaje dużym wyzwaniem. Istotne znaczenie będą miały dalsze inwestycje w rozwój AI oraz stabilne warunki dla firm działających w tym obszarze.
– Mocno trzymam kciuki za modele europejskie, w tym naturalnie przede wszystkim za polskie rozwiązania. Na ich wyniki należy patrzeć szeroko, mając też na uwadze chociażby wielkość modeli czy skalę inwestycji. Mam nadzieję, że przed nami wiele mądrych decyzji, które będą służyć rozwojowi AI i ogólnie technologii – dodaje Marek Jeleśniański.
Pełny raport z badań i ranking modeli językowych dostępny jest pod adresem:
jelesnianski.pl/badania-llm/
O firmie Oxido
Oxido to firma istniejąca od 2009 roku, od kilku lat skoncentrowana na wykorzystaniu sztucznej inteligencji.


